

AI Agents at Work

The past year has seen the emergence of benchmarks that test AI “agents” in realistic work settings, moving beyond static Q&A exams. Two notable benchmarks – TheAgentCompany (by a Carnegie Mellon-led team) and CRMArena-Pro (by Salesforce AI Research) – evaluate how well large language-model (LLM) agents perform complex, multi-step tasks with tools, data, and even simulated coworkers. The results carry a sobering message for executives: today’s best LLM agents can autonomously handle only a fraction of real-world tasks, and they struggle especially with long processes and strict policy constraints. TheAgentCompany’s simulated software-company environment found its top AI agent (Google’s Gemini-2.5-Pro) fully solved only about 30 % of 175 diverse tasks. CRMArena-Pro, focused on customer-relationship workflows, saw leading models hit ~58 % success on single-step queries, but drop to ~35 % when multiple back-and-forth interactions were required. In both benchmarks, simpler routine tasks (like following a defined workflow) proved far more tractable than open-ended reasoning or compliance checks. For instance, in CRMArena-Pro the best agents achieved 83 %+ accuracy on straightforward Workflow Execution tasks, yet showed near-zero “common-sense” awareness of data confidentiality (often divulging sensitive info unless explicitly coached). Catalaize Insight: These findings imply that while LLM agents can already automate some low-level office tasks, they remain unreliable for complex decision-making or handling sensitive data without human oversight. For C-level leaders, the takeaway is clear: treat current AI agents as junior assistants, not autonomous executives. Companies should prioritize use cases where today’s agents excel (e.g., data retrieval and rote processes), put guardrails around confidential data, and expect to invest in human-in-the-loop supervision for the foreseeable future. Meanwhile, investors and strategists should temper expectations of near-term labor displacement and focus on tools that enhance human productivity rather than replace it. The benchmarks underscore sizeable gaps – in multi-step reasoning, compliance, and robustness – that next-generation AI must close before “digital workers” can truly earn a spot on the org chart.
Why Benchmarks for Agents Matter
The early 2020s saw a boom in “agentic” AI – systems like AutoGPT and others that attempt to plan and execute tasks autonomously by chaining LLM outputs. This raised hopes (and fears) that AI could perform complex workflows like a human employee. However, classical NLP benchmarks (e.g., MMLU for knowledge, GSM8K for math) don’t capture the realities of these scenarios. Solving a math word problem or coding challenge is one thing; completing a realistic business task (say, triaging a customer request via a CRM app, or debugging a codebase by reading docs, writing code, and testing it) is quite another. Static benchmarks isolate a narrow skill in a vacuum. By contrast, an AI agent in the wild must integrate skills – understanding instructions, querying databases, using tools or APIs, collaborating with humans – all while respecting constraints like security policy. Traditional one-turn Q&A tests fail to measure the coordination, contextual adaptation, and tool-use proficiency that true autonomy demands. In short, new benchmarks were needed to answer the pressing question: Can LLM-driven agents really do my job? – and if not, where do they fall short. TheAgentCompany and CRMArena-Pro were created to fill this gap, providing rigorous “flight simulators” for AI worker bees. They drop AI systems into realistic corporate sandboxes and score how well they perform end-to-end tasks. This shift from quiz-style evaluation to workflow evaluation is crucial: it moves us from knowing what a model knows, to understanding what it can actually do. For businesses eyeing automation, these agent benchmarks offer a dose of reality and a yardstick for progress.
Benchmark Deep-Dive & Comparison

TheAgentCompany (TAC) Benchmark
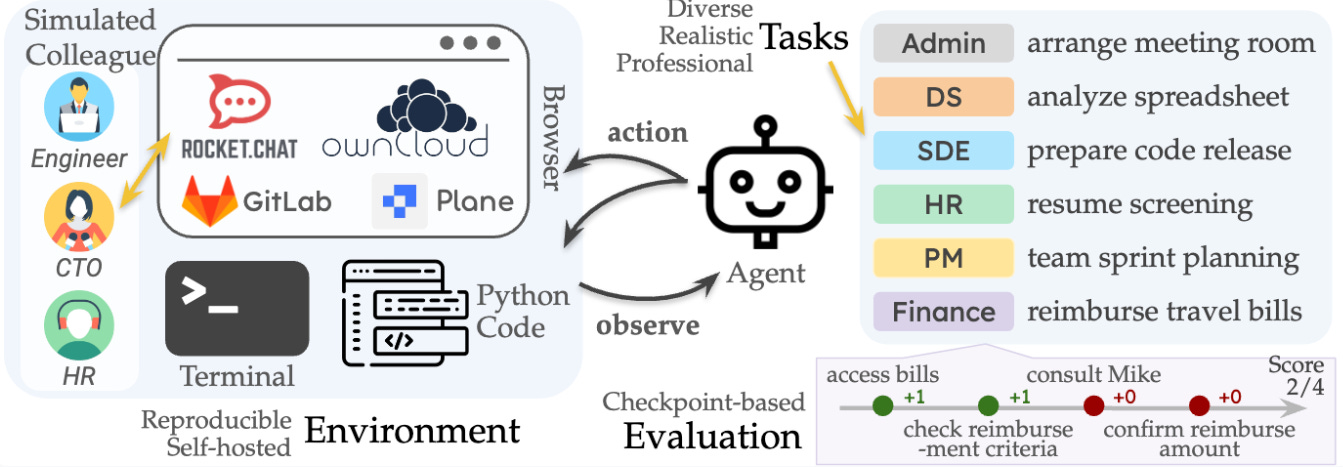
Design & Goals: TheAgentCompany benchmark targets general office work in a simulated software company. It aims to evaluate agents acting as “digital workers” who can use typical corporate tools: web browsers (for intranet sites), code editors, terminals, and chat clients. To that end, the authors built a self-contained sandbox environment mirroring a tech company’s IT stack. This environment includes realistic internal services – e.g. a GitLab code repository, a project-management system (“Plane”), a cloud-storage drive (ownCloud), and a corporate chat (Rocket.Chat) – all pre-populated with dummy data. The design goal was high realism: an AI agent must navigate these apps just as a remote employee would, performing tasks like reading documentation, updating spreadsheets, fixing bugs, or coordinating with a coworker.
Tasks & Tools: TAC comprises 175 distinct tasks spanning roles like Software Engineer, Data Scientist, Product Manager, HR, Finance, and IT Admin. Tasks range from coding and data analysis to drafting emails and handling support tickets. Critically, many tasks require multi-step tool use. For example, an agent might read a policy on the intranet, draft a response in a Word doc on ownCloud, and finally email a colleague. Tools available include web browsing (for the internal sites), running code or scripts, and “communicating” via the chat – sometimes even delegating subtasks to a simulated coworker bot. Success criteria are defined via checkpoints: each task is broken into subtasks with verifiable outcomes, allowing partial credit for incomplete solutions. This means an agent that makes some progress (e.g. creates a required file but with errors) can still earn points short of full success.
Environment Realism: To run TAC, one must launch a Dockerized mini-intranet of roughly 30 GB – underscoring the level of detail baked in. The internal web services come with realistic content (documents, code repositories, user accounts, etc.), so the agent’s “world” is rich but also closed (sandboxed): it’s a fake company internet, not the true live internet. This ensures reproducibility and confidentiality (no real customer data). However, it also means the agent isn’t tested on unforeseen web content – rather, it’s challenged to navigate a complex but static company knowledge base and toolset. In essence, TAC strikes a balance between open-world chaos and overly scripted tasks, by providing a constrained yet multifaceted digital workplace.
Baseline Results: TAC’s creators evaluated 12 LLM-based agents (using different model back-ends and agent frameworks). The headline result: even the best model could autonomously complete only ~30 % of the tasks. Google’s Gemini-2.5-Pro agent was top performer at 30.3 % full-task success (39.3 % with partial credit), edging out Anthropic’s Claude-3.7 and others. In practical terms, this agent solved 53 out of 175 tasks outright – mostly the “low-hanging fruit.” Many simpler tasks (single-app or short horizon) were done correctly, while anything long-horizon tended to fail partway. Notably, performance came at a cost: the Gemini agent averaged 27 steps and about $4.20 in API calls per task, due to lengthy reasoning and tool use. Less-capable models often got stuck in loops or wandered aimlessly, inflating step counts without improving outcomes. A smaller variant, “Gemini-2.0-Flash,” was far cheaper (< $1 per task) but managed only ~11 % success, highlighting a trade-off between capability and cost. Open-source models (Meta’s Llama 3.1 and Alibaba’s Qwen) lagged well behind proprietary ones, topping out under 8 % success – although a new 70-B-parameter Llama-3.3 showed promise by matching the older 405-B Llama at ~7 % success with much lower cost. Another finding was that agent strategy matters: a single-agent approach (OpenHands CodeAct with GPT-4) outperformed a multi-agent scheme (CAMEL’s OWL RolePlay with GPT-4), 8.6 % vs 4.0 % success, because multi-agent coordination broke down on long tasks. Overall, TAC’s baseline paints a nuanced picture: current frontier models can tackle certain well-scoped tasks in a simulated office, but most tasks – especially those requiring extended planning or complex UIs – remain unsolved. Agents struggled with tasks involving the corporate chat (social reasoning) and online Office docs, often failing to handle these interactive interfaces. Coding tasks were relatively higher-scoring, suggesting that today’s LLMs’ coding proficiency gives them an edge on software-engineering chores compared with, say, HR tasks involving forms and scanned documents.
Unique Contributions: TheAgentCompany’s benchmark is innovative in its breadth of task types and integrated environment. It evaluates an agent in a near-real corporate IT ecosystem (with all the attendant distractions and tool complexities). The benchmark is also extensible and open-sourced – researchers can add new tasks or swap in new agent frameworks easily. Another novelty is the partial-credit scoring for long tasks, which offers a more graded assessment than pass/fail and pinpoints where agents get stuck. Finally, TAC’s use of real open-source software (such as actual GitLab and chat servers) sets a high bar for realism; it surfaces issues like session time-outs, web-UI quirks, or needing to log in – challenges that paper-and-pencil benchmarks would never encounter. In short, TAC contributes a testbed that looks and feels like a real workplace, pushing agents to demonstrate workplace competency rather than just test-taking skills.
CRMArena-Pro Benchmark
Design & Goals: CRMArena-Pro is a benchmark squarely focused on Customer Relationship Management (CRM) – customer support, sales operations, and B2B/B2C sales processes. It expands an earlier CRMArena benchmark beyond customer-support FAQs into a broader set of business scenarios. The goal is a “holistic and realistic” assessment of LLM agents in enterprise contexts, emphasizing diverse interaction types. CRMArena-Pro defines 19 distinct task scenarios across three main areas: customer service, sales, and configure-price-quote (CPQ). These tasks were vetted by domain experts to ensure realism and relevance. The benchmark emphasizes multi-turn interactions – many tasks simulate a dialogue between user and AI agent rather than a one-shot question. It also explicitly tests the agent’s ability to handle confidential information properly, a key business concern.
Environment & Tasks: CRMArena-Pro provides a full sandbox CRM environment modeled on the Salesforce platform. Two synthetic Salesforce orgs were built: one B2C and one B2B, populated with thousands of customer records, support cases, sales opportunities, knowledge-base articles, and policy documents – 54 k records for B2C and 29 k for B2B, covering 25 standard CRM objects plus textual data like call transcripts and emails. Agents interact via a GUI or via APIs; for benchmarking, API mode lets agents query data or search the knowledge base programmatically. At each turn an agent can either make an API call (e.g. run a query) or respond to the user. Each task scenario is a mini-dialogue: it starts with a user request, and the agent is expected to complete the task through multiple question/answer turns and data-retrieval actions. For example, a sales task might be: “Generate a price quote for customer X’s requested product bundle.”
CRMArena-Pro’s tasks span four “business-skill” categories:
Database querying & computation (structured data retrieval and math)
Textual information retrieval & reasoning (searching docs or logs to answer)
Workflow execution (following a defined CRM procedure)
Policy-compliance checking (ensuring a solution or offer meets rules)
Each task is formulated for both orgs, yielding 38 distinct scenarios, and 100 instantiations of each scenario are generated – 4 280 query instances in total. Success is measured as the fraction of instances answered correctly.
Success Criteria: For each instance, ground truth is known. CRMArena-Pro tracks performance separately for single-turn vs multi-turn settings. In single-turn mode the agent must answer immediately; in multi-turn mode it can ask clarifying questions. The benchmark also includes confidentiality test queries where the correct behavior is to refuse or sanitize the response. GPT-4 is used as an automated evaluator for confidentiality, judging whether an answer is appropriately protective.
Baseline Results: State-of-the-art models were evaluated. Gemini-2.5-Pro topped the chart with about 58 % success on single-turn queries. In multi-turn mode even Gemini fell to roughly 30–35 %. Allowing dialogue did not improve accuracy; it introduced more failure modes. Workflow-execution tasks were easiest (Gemini solved over 83 % of them in one turn). Database queries with computation had moderate success; heavy textual-reasoning or cross-record policy checks were much harder (often under 40 % even single-turn). Crucially, confidentiality tests were a near-complete failure out-of-the-box – models showed “near-zero inherent confidentiality awareness.” Prompt tuning to enforce caution improved refusals but often hurt task performance, underscoring the alignment challenge. Differences between B2B and B2C contexts were small overall, but no current model approached human-level reliability. The authors conclude there is a significant gap between current LLM capabilities and real-world enterprise demands, especially for multi-turn reasoning and confidentiality.
Unique Contributions: CRMArena-Pro combines realistic enterprise data, interactive dialogue, and policy checks in a single benchmark. It is among the first to incorporate a confidential-information safeguard test, critical for enterprise AI deployment. Covering both B2C and B2B scenarios acknowledges that enterprise agents must handle complex multi-stakeholder processes, not just consumer chats. Large-scale evaluation (100 instances per task) gives statistically robust results. CRMArena-Pro is open-sourced with data, tooling, and even a live Salesforce org for researchers. It pushes beyond FAQ-style benchmarks into tasks like Configure-Price-Quote, which blend numeric calculation with rule adherence. Overall, it offers a test suite grounded in authentic business workflows, emphasizing multi-turn and multi-modal interactions that earlier benchmarks neglected.
Side-by-Side Comparison
To summarize the two benchmarks, the table below highlights key similarities and differences:

Methodological Critique
Both benchmarks represent a big step forward in evaluating AI agents, yet each has methodological limitations to consider. Experimental rigor and statistical validity differ between them. CRMArena-Pro’s use of 100 randomized instances per task lends confidence that results aren’t flukes – one can compute error bars and observe variability across runs. TheAgentCompany, by contrast, uses 175 one-off scenarios. While that’s a wide sample, it’s effectively n = 1 per task type, so results could be sensitive to the specific phrasing or scenario setup. TAC mitigates this somewhat by scoring partial progress; however, without multiple trials on variations of each task, it’s harder to assess statistical significance of small differences (e.g. whether Claude-3.7’s 26 % vs Claude-3.5’s 24 % is meaningful or noise). Future agent benchmarks might combine both approaches: diverse scenarios and multiple instance variations for robustness.
Reproducibility and hidden “deployment” costs are another concern. TAC’s fully-fledged environment is impressively realistic – but also cumbersome to set up, requiring dozens of Docker containers and > 30 GB disk space. For many researchers (or enterprises wanting to test an agent), this heavy lift could be a barrier. Moreover, running the benchmark with frontier models is expensive: as noted, Gemini-2.5-Pro consumed ~$4 of API credits per task on average. Evaluating all 175 TAC tasks on that model cost ~$700 in API fees; CRMArena-Pro with 4 280 queries would be even costlier if using GPT-4 for each query. This raises an interesting point: the monetary cost of agentic reasoning becomes a factor in benchmark design. If a benchmark encourages extremely long chains of reasoning, it might favor models that “know when to quit” to save cost – a dynamic not present in traditional benchmarks but very relevant in practice. TheAgentCompany authors actually observed GPT-4 sometimes wisely gave up on hopeless tasks, saving steps (and money), whereas open models plodded on fruitlessly. Such behaviors complicate how we define the “best” agent – is it the one with highest success rate at any cost, or the one that balances efficiency?
Evaluator bias is an important issue as well. Both benchmarks rely on some amount of automated evaluation. CRMArena-Pro in particular uses an LLM-as-judge to evaluate qualitative aspects like whether an answer violates confidentiality. Recent studies have highlighted that LLM evaluators can carry biases – for example, favoring answers written in a style they prefer, or even showing “self-preference” bias (overrating outputs from the same model family). In CRMArena-Pro’s case, GPT-4 was used to judge confidentiality breaches; one might wonder, would a GPT-4 judge be more lenient to a GPT-4 agent’s style of refusal versus another model’s? The benchmark designers likely tried to minimize bias via carefully crafted evaluation prompts, but it remains a concern. TheAgentCompany mostly avoids LLM-based scoring by using predetermined checkpoints and expected outputs (e.g. does file X exist? does it contain Y?) for objective tasks. However, for subjective tasks (like writing an email draft), they don’t detail how quality was evaluated – potentially those were simplified to binary criteria (email sent or not). Overall, the use of AI to evaluate AI introduces the possibility of systematic bias², and future benchmarks may need to incorporate human evaluation or adversarial tests to validate AI judges.
Another consideration is external validity: do these sandbox results predict real-world performance? Both benchmarks use synthetic data and controlled environments. This is a double-edged sword. On one hand, it ensures a fair, apples-to-apples test (every agent faces the exact same scenario and data). On the other hand, reality is messier. For TAC, one could argue that real corporate environments have unpredictability (unknown websites, software updates, human coworkers who don’t follow scripts). TAC’s closed-world tasks might understate those challenges – agents could overfit to the sandbox’s quirks. Similarly, CRMArena-Pro’s data, while extensive, is still generated. Real customer conversations can be more colloquial or hostile than the “diverse personas” simulated. And a real CRM may contain dirty data and exceptions that a curated dataset lacks. Thus, a model scoring 58 % on CRMArena-Pro might score lower when deployed in an actual call center. Benchmark gaming is also a risk: once a benchmark is published, there’s potential for models to be fine-tuned on it or hard-coded to its specific formats. This is especially plausible for CRMArena-Pro, since the dataset is public; a less scrupulous team could train an agent on those 4 280 QA pairs, defeating the benchmark’s purpose. TheAgentCompany’s tasks (with complex multi-step solutions) are harder to memorize, but not impossible to script for if someone tailored an agent policy explicitly for each known task. The best defense is to regularly update benchmarks (e.g. add new tasks) and to treat them as diagnostic tools, not final exams. In practice, an agent proving itself in these benchmarks is necessary but not sufficient for production readiness.
Finally, “agent-as-evaluator” paradoxes come into play. One emerging challenge: if an autonomous agent can decide how well it did (self-evaluation), it might terminate early thinking it’s done when it isn’t. Neither TAC nor CRMArena allow agents to grade themselves (they have external evaluators), but as agents become more self-directed, ensuring they accurately judge success will matter. Likewise, multi-agent benchmarks (like evaluating agents working in teams) will need to consider how to score collective performance and whether agents might collude or cover for each other’s mistakes. These nuances highlight that we are still in the early days of agent benchmarking methodology. The current benchmarks are valuable prototypes, but the field must remain vigilant about validity, bias, and evolving the tests as agents get more sophisticated.
Implications for Enterprise Adoption
From a business perspective, these benchmark outcomes offer both caution and insight on the road to AI-enabled operations. For one, the relatively low task success rates signal that full autonomy is out of reach for now. Even in a controlled sandbox, the best AI could only do about one-third of the job correctly end-to-end. In a live enterprise setting, that likely translates to needing human oversight on most tasks. An AI agent might draft an email or pull a report, but a human will need to review and finish the task – otherwise there’s a high risk of error or an incomplete result. This suggests that, in the near term, AI agents are best used as assistants rather than replacements. They can accelerate workflows by handling grunt work (e.g. retrieving data, initial drafts), but handing them the keys to execute customer requests start-to-finish is risky.
The benchmarks also reveal a split between different types of tasks, which maps to deployment strategy. Tasks requiring straightforward procedure following or structured data retrieval are within current AI capabilities (with success rates well above 80 % in the easiest cases). These are prime candidates for early automation. For example, an agent could auto-generate weekly sales summaries or update CRM records according to a set template – things that are laborious but follow clear rules. Indeed, CRMArena-Pro showed Workflow Execution tasks were low-hanging fruit for AI. On the flip side, tasks that involve judgment calls, complex rules, or creative problem-solving remain hard. Policy compliance is a big one: agents struggled to apply intricate business rules or spot policy violations. In a deployment context, that means an AI assistant might unknowingly break company policy (e.g. offer an unauthorized discount or share prohibited information) unless tightly constrained. Enterprises must therefore sandbox agent actions and perhaps require approval for any decision with compliance impact. Likewise, TheAgentCompany’s findings that agents do poorly at “soft” tasks (like HR or admin work requiring interpersonal nuance or reading a graphic) suggests those areas are not quick wins for AI. An attempt to use an AI agent as an HR helpdesk clerk, for instance, could backfire if the agent misunderstands a query or responds insensitively.
Another implication is the need for robust guardrails around confidential data. CRMArena-Pro’s confidentiality tests were essentially failed by default. That means if you connect an LLM agent to your customer database, it will happily output private data if asked, unless you explicitly prevent it. Organizations looking to deploy agents on internal data should invest in safety layers – for example, role-based access controls, redaction filters, or an intermediary policy model that vets the agent’s outputs. Relying on the base LLM to “know” what not to reveal is not sufficient (current models clearly don’t). The need for confidentiality adherence might even slow adoption in industries like finance or healthcare until solutions mature.
The benchmarks also underscore multi-turn reliability as a bottleneck. Many real-world workflows involve clarifying requirements or gathering incremental info (no one provides all details perfectly in one message). Yet, results show agents in multi-turn settings got less accurate and sometimes meandered. This implies that using AI in customer-facing chat or multi-step ticket resolution could lead to frustrated users if the agent loses context or asks irrelevant questions. Enterprises might circumvent this by constraining agents to one-shot tasks for now (like a chatbot that always either gives an answer or escalates after one exchange, rather than an extended dialogue). Until models handle dialogue better, keeping interactions brief and bounded will reduce failure points.
From an ROI standpoint, these limitations mean that the immediate gains from LLM agents may be incremental, not transformative. Yes, some tasks can be accelerated – for example, an agent that can auto-fill forms or suggest responses might save employees minutes here and there. But the fact that best-case automation was ~30 % of tasks in TAC means 70 % still required human work. So we’re looking at productivity boosts, not full task offloading. For strategic planning, this suggests a gradual ramp rather than a sudden jump in workforce impact. Companies might redeploy time saved on routine sub-tasks to higher-value work, rather than cut staffing outright. Furthermore, the cost factor highlighted by TAC can’t be ignored. If an AI agent uses a $0.10 API call 40 times to do one task, that might eat up any efficiency gains. Enterprises will need to carefully choose where an agent genuinely adds value net of its operating cost – e.g. using smaller models or local models for high-volume simple tasks, and reserving expensive calls for the truly complex queries where they’re worth it.
On a more optimistic note, these benchmarks also point out what current agents do well, which can guide deployments. TheAgentCompany’s analysis noted that coding tasks were relatively successful. So using LLM agents for internal code assistance, script generation, or debugging support is a promising avenue (indeed already happening via GitHub Copilot and similar tools). Similarly, CRMArena-Pro showed agents excel at process automation when the steps are explicit. So automating things like data entry workflows or simple approval processes might be low-risk and high-reward. In those domains, an AI agent can act almost like a very fast macro, reliably executing the known steps (and unlike a hard-coded RPA script, it can handle slight variations in instruction thanks to language understanding).
In summary, enterprise adopters should interpret these benchmarks as a reality check: today’s AI agents are powerful but fallible interns, not seasoned specialists. They will require training, supervision, and gradual integration. Leaders should identify niches where agents consistently match human-level performance and start there, while devising fallback plans for the many cases where they don’t. The fact that even state-of-the-art models capped out well below human performance (~58 % best-case) is a reminder that ROI will come from human-AI teamwork in the near term, not AI autonomy in isolation.
Future Directions & Open Questions
Where do we go from here? The benchmarks reveal clear technical gaps that future research needs to address. One big area is planning and long-horizon reasoning. Agents need better algorithms to decompose complex tasks, remember what’s been done, and avoid redundant or cyclical actions. This could involve enhanced internal planning modules or hybrids of LLMs with classical planners. Some research (e.g. “Tree of Thoughts” prompting or tool-aware planning models) is already probing this, but benchmarks like TAC show even advanced agents often fumble multi-step plans (like the OWL multi-agent getting stuck due to forgetting past context). Memory and state tracking are related challenges – current agents have limited context windows and no long-term memory of past actions. We may see development of vector database memory stores or scratchpad approaches that the agent can consult as it works. Having a persistent memory could prevent mistakes like asking the same clarification twice or losing info between turns (which likely plagued some CRMArena multi-turn failures).
Another crucial direction is improving tool use and API integration. Today’s agents treat tools somewhat blindly – they formulate an API call in natural language (or pseudo-code), execute it, then parse the result. More robust integration (e.g. agents being aware of API schemas, handling errors gracefully, or learning tool semantics) will make them far more reliable. We might envision a future benchmark where agents have a formal API specification to work with, and the challenge is to use it optimally. Efforts like Microsoft’s “Guidance” and OpenAI’s function calling move in this direction by constraining outputs to tool-friendly formats. If future benchmarks incorporate those, we’d likely see a jump in success rates for data retrieval tasks.
Safety and alignment will also be front and center. The near-zero confidentiality awareness found in CRMArena-Pro is concerning. Future agent models may need dedicated sub-systems for compliance – essentially a built-in governor that checks “Is this action allowed?” before executing. Research on AI that can internally simulate an auditor or leverage formal rule-checking (like turning policies into machine-checkable rules) would directly impact benchmarks focusing on policy adherence. Additionally, as benchmarks expand to more domains, ethical and fairness considerations will arise: e.g. agents in hiring or lending scenarios must be tested for bias. We may see new evaluation dimensions added to benchmarks (did the agent’s decisions show unfair bias? did it hallucinate and propagate misinformation?), not just task completion.
On the benchmarking front itself, expect new and complementary benchmarks to emerge. TheAgentCompany and CRMArena-Pro target certain domains; others will fill gaps. For example, we might see a financial analyst agent benchmark (testing portfolio management or accounting tasks) or a medical assistant benchmark (simulating patient triage or medical record analysis). Indeed, Salesforce’s work hints at interest beyond CRM to general enterprise processes. Academia is also active: prior benchmarks like WorkBench, TauBench, and others focused on slices of this problem – these will likely iterate and become more comprehensive. There’s also the question of multi-agent collaboration: future benchmarks may evaluate teams of AI agents working together (or with humans) on a task, which raises evaluation complexity but mirrors real multi-agent scenarios (e.g. an AI finance team preparing a quarterly report with different agents handling data, narrative, etc.). Open questions abound: How do we measure the effectiveness of an AI co-worker in a human team? What new failure modes appear when two agents talk to each other? These are fertile ground for research, and we might see benchmark offshoots that isolate those aspects (some early efforts like CAMEL’s multi-agent roleplay have surfaced issues like context loss across agents).
Regulators and standards bodies are paying attention as well. It’s conceivable that industry groups or governments will develop standard evaluation suites to certify AI agents for certain uses. For instance, before an AI agent could be allowed to handle customer data in Europe, regulators might require it passes a benchmark of confidentiality and accuracy (perhaps using something like CRMArena-Pro as a template). Organizations like NIST might create reference tasks for “AI system reliability” akin to how they have for cybersecurity drills. The current benchmarks can inform those by highlighting key axes of performance. They also expose where lack of standards could be dangerous (e.g. if companies deployed agents without testing for policy compliance, as these benchmarks do, problems would ensue). We may see benchmark-driven checklists or best practices entering compliance guidelines (for example, a finance regulator might say: prove your trading bot won’t leak client data by showing it scores above X on a relevant benchmark). In short, today’s research benchmarks could evolve into industry benchmarks that define acceptable performance for AI in critical roles.
A few open questions remain unsolved: How can we ensure benchmark relevance over time? (Agents might improve quickly on today’s tasks – will benchmarks be updated or risk becoming obsolete like some academic tests did?) Can we create benchmarks that evaluate generalization? (Right now, an agent could potentially be tuned to these exact tasks; a truly robust agent should handle novel tasks too. Future evaluations might randomize task details or include secret test tasks to prevent overfitting.) And what about human-agent interaction quality? None of the current benchmarks directly measure user satisfaction or trust – yet in deployment that’s crucial. We might need to include human feedback or ratings as part of the benchmark score in future.
In sum, the path forward will involve simultaneously building better agents (with improved reasoning, memory, tool-use, and safety) and building better benchmarks to measure those improvements across more scenarios. TheAgentCompany and CRMArena-Pro have laid a strong foundation, but the job of benchmarking “AI workers” is just getting started.
Actionable Recommendations
For CTOs / Heads of AI:
Start with Narrow, High-Value Use Cases: Identify repetitive, well-structured tasks (data entry, report generation, simple customer Q&A) where current LLM agents perform best. Pilot AI assistants there first, where they’re likely to succeed. Avoid immediately deploying agents on complex decision-making or sensitive client interactions which the benchmarks show are error-prone.
Keep Humans-in-the-Loop: Implement a human review or approval step for any critical action the agent takes. Given that even top agents complete only ~30% of complex tasks autonomously, design workflows so that AI outputs (emails, analyses, policy decisions) are vetted by staff until the agent consistently earns trust on a specific task.
Invest in Agent Guardrails: Develop clear policy rules and integrate them into the agent’s prompting or system APIs. Since agents won’t inherently know your company’s confidentiality or compliance requirements, encode those as hard constraints (e.g. “never reveal X”, or require the agent to call a validation function before sending out information). Consider sandboxing the agent’s access – e.g. limit which data fields it can query – to prevent accidental leaks.
Monitor Cost vs. Benefit: Track how many tokens/API calls your AI agent uses to accomplish tasks. TAC showed some agents looping uselessly– which in production wastes time and money. Set thresholds or use cheaper models for tasks that don’t need GPT-4-level intelligence. Optimize prompts to be succinct. Essentially, manage your “AI compute budget” like you would any cloud resource, ensuring the ROI stays positive.
Continuous Evaluation & Training: Adopt the mindset that your AI agent is a constantly learning junior employee. Regularly evaluate it on internal benchmarks or samples of real tasks (possibly adapting public benchmarks like these to your data). Use failures as training data – either via fine-tuning or prompt adjustments – so the agent improves over time on your specific workflows. Also stay updated on new model releases: a model that scores 60% today might be eclipsed by one scoring 80% next year on these benchmarks, which could rapidly change your automation calculus.
For Investors / Market Analysts:
Temper Short-Term Automation Expectations: These benchmarks indicate that claims of AI agents soon replacing large swaths of white-collar jobs are premature. If the best enterprise AI can only solve ~1/3 of simulated tasks without help, real-world impact will be more incremental than revolutionary in the next 1–2 years. Evaluate companies on augmentation (how AI boosts human productivity) rather than pure headcount replacement narratives.
Focus on the “Picks and Shovels”: The complexity of deploying AI agents (from needed infrastructure like the 30 GB environments to guardrail software) suggests opportunity in the tooling layer. Look for startups building agent platforms, monitoring tools, or safety layers that enterprises will need to operationalize LLM agents. Those providing the scaffolding – reliable tool APIs, memory stores, compliance modules – will be in demand as companies experiment with AI coworkers.
Watch for Domain-Specific Wins: General-purpose agent platforms are struggling broadly, but there may be specific domains where the benchmarks show high performance that a savvy company can capitalize on. For instance, an AI sales email generator or code assistant is more viable today than an AI HR assistant. Back startups that smartly target niches aligned with current model strengths (e.g. coding, structured queries) and that have a plan for the weaknesses (dialogue control, etc.).
Evaluate AI Promises with Benchmarks: When a venture pitch or public company touts its AI agent can do X, ask if they’ve validated on benchmarks like these. Insist on seeing evidence: e.g. does their internal model beat GPT-4 on CRMArena-Pro tasks? The existence of open benchmarks means it’s easier to cut through hype. A company claiming “autonomous AI agents” but avoiding standardized evaluations might be overpromising. Use benchmark performance as one yardstick of technical moat and progress.
Anticipate a Second-Mover Advantage: Given the fast-evolving landscape, the best investments may be those poised to leverage next-generation models on these benchmarks. Today’s leaders (OpenAI, Google) have an edge, but the benchmarks show ample room for improvement – which agile newcomers or open-source collaborations could fill. Keep an eye on research – e.g. new planning techniques or a breakthrough model that suddenly jumps success from 30% to 60%. The field is in flux; don’t lock in assumptions that current winners will remain on top if/when these agent success rates double with new tech.
Bibliography
Disclaimer
The content of Catalaize is provided for informational and educational purposes only and should not be considered investment advice. While we occasionally discuss companies operating in the AI sector, nothing in this newsletter constitutes a recommendation to buy, sell, or hold any security. All investment decisions are your sole responsibility—always carry out your own research or consult a licensed professional.