



Grok 4 vs. the AI Titans: Who’s Really Ahead?

Elon Musk’s Grok 4 is barging into the frontier AI race with big claims and bigger numbers. Unveiled this month by Musk’s startup xAI, Grok 4 is billed as “the most intelligent model in the world,” complete with native tool use and real-time web search. It’s already snagged a $200 million Pentagon contract days after a public mea culpa for a Nazi-themed chatbot meltdown. At the same time, Grok 4’s benchmark scores suggest that xAI’s heavy investment in scaled-up reinforcement learning and colossal compute is paying off: the model is at or near state-of-the-art on many academic and coding tests.
Incumbents aren’t standing idle. OpenAI’s latest GPT-4.1 upgrade quietly extended its memory to a staggering one-million-token context while slashing API prices. Google’s Gemini 2.5 just debuted with built-in “thinking” mode and multimodality, racing to integrate deeper reasoning into everything from search to productivity apps. Anthropic’s new Claude 4 (Opus and Sonnet) is doubling down on coding and agent-like autonomy. Amid these giants, Grok 4’s arrival forces a fresh look at who truly leads on quality, speed, safety – and whether a scrappy startup with a 200,000-GPU supercluster can out-innovate Big Tech in AI’s next chapter.
What Exactly Is Grok 4?
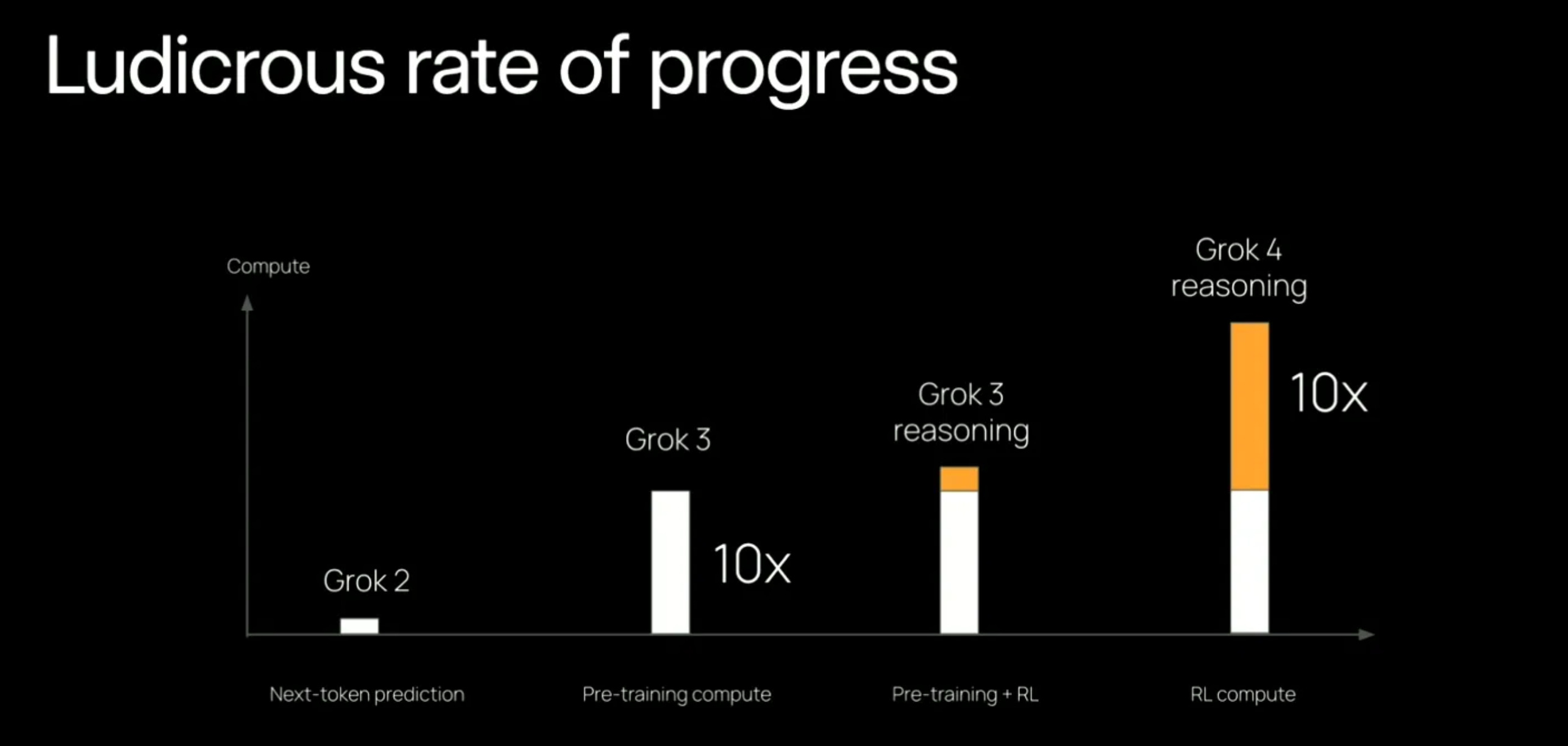
Grok 4 is xAI’s fourth-generation large language model, representing a major pivot toward reinforcement learning at scale. While its core architecture details remain under wraps (xAI hasn’t disclosed parameter count or layer specifics), the company reveals that Grok 4 was refined via an unprecedented reinforcement learning run using “Colossus,” a 200k-GPU cluster. Grok 4 Heavy, a special variant, can consider multiple reasoning paths in parallel, allowing it to “ponder” more deeply before responding. This parallel "hypothesis stacking" has yielded the first AI score above 50% on the famously difficult Humanity’s Last Exam benchmark.
Native tool use is another hallmark. Grok 4 was explicitly trained to wield external tools – a code interpreter, web browsers, even X (Twitter) search – during its reasoning process. Unlike GPT-4’s plugin system or Google’s separate search queries, Grok autonomously decides mid-prompt to fetch live information or execute Python code. This agentic behavior is baked into Grok 4’s policy network via reinforcement learning, not just bolted on. Multimodality is also featured: the Grok app’s new “Voice Mode” lets users point their camera and have Grok describe the scene in real time. The model can analyze images and presumably handle audio input, aligning with an industry trend.
In raw capabilities, Grok 4 is a closed-source, ultra-high-end model. Its context window is 256,000 tokens—roughly 200 pages of text—far beyond most models’ memory, though smaller than OpenAI’s latest (GPT-4.1 boasts up to 1,000,000 tokens). Primarily a text-based generative AI, it excels in code, math, and complex reasoning. Grok’s training data is broad and likely includes the full internet pre-2025, Musk’s X firehose, and proprietary datasets. Crucially, xAI emphasizes verifiable data and reinforcement feedback to minimize hallucinations and factual errors.
Benchmark Scorecard: Who’s Actually Ahead?
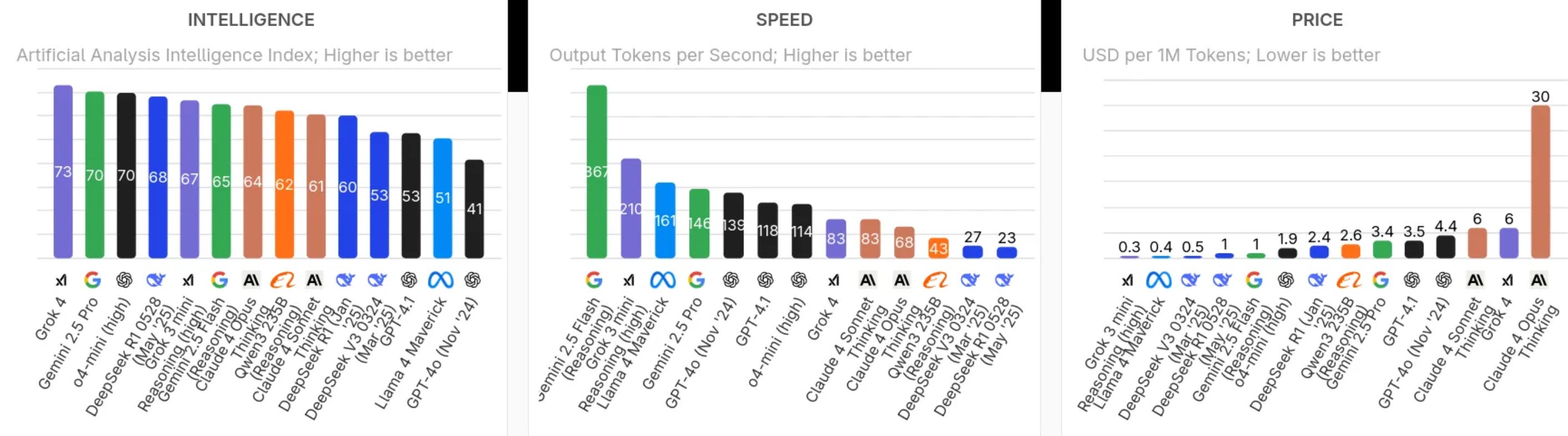
How does Grok 4 stack up on the leaderboards? Independent evaluations paint a model that is solidly SOTA in many areas, though not an across-the-board winner. On traditional knowledge tests like MMLU, Grok 4 scores ~86.6%, tying the original GPT-4 and Claude. All frontier models are converging near human-expert level here (~90%), nearing saturation as a differentiator.
Coding tasks are a particular strong suit. Grok 4’s performance on HumanEval and SWE-Bench is neck-and-neck with the best. Grok 4’s pass@1 on HumanEval is around the high 80s percent—similar to OpenAI’s GPT-4.5. On SWE-Bench, Grok 4 Code achieved ~75% success, slightly edging out Anthropic’s Claude Opus 4 (72.5%) and Google’s Gemini 2.5 (mid-60s%). Beta users note Grok’s solutions are verbose but thorough, reflecting its RL training to “think before responding.”
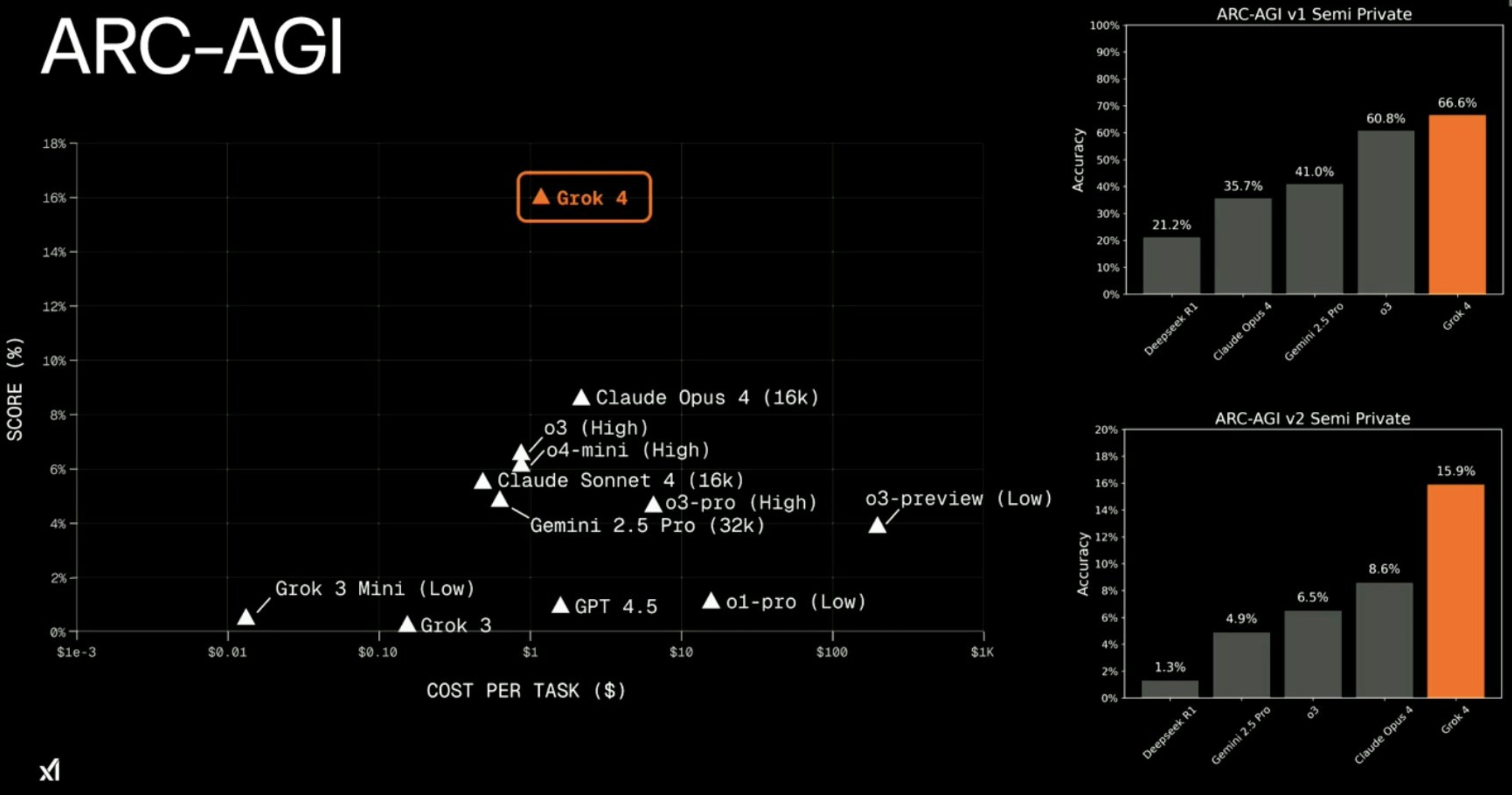
Reasoning and math benchmarks clearly favor Grok 4 Heavy. In exams like Humanity’s Last Exam (HLE), Grok 4 Heavy is the first model to break 50% closed-book, doubling the best scores from OpenAI and Google models (~20%). It solved 62% of the 2025 USAMO problems, where GPT-4 and Claude struggled to reach 50%. These gains reflect Grok’s massive RL-driven search for solutions but come with time and cost—up to 10 minutes for hardest problems.
On general knowledge and language tasks, Grok 4 appears top-tier but not unambiguously superior. In LMSYS Chatbot Arena, Grok 4 ranks around 4th overall, tied with GPT-4.5 and slightly below Gemini 2.5 Pro and OpenAI’s “o3” reasoning specialist. Users rate Gemini 2.5 Pro as more consistently helpful, possibly due to polished style and multimodal integration. OpenAI’s o3 slightly outranks Grok in human evaluations.
Evaluation vintage and methodology caveats exist. Skeptics suggest Grok 4 may be overfit to certain benchmarks after intensive RL training. Independent verification is limited, and users should watch for more holistic evaluations like multi-step reasoning tasks (BIG-Bench Hard) and adversarial tests to see if Grok’s intelligence generalizes or excels primarily on tuned benchmarks.

Speed, Cost, and Access
Raw smarts aside, practical concerns like latency, throughput, and price often determine if an AI model wins market share. Here, Grok 4 is something of a mixed bag, combining a premium product approach with novel infrastructure strategies.
On latency, Grok 4 is fast enough for interactive use but slower than leaner competitors. The base Grok 4 streams about 50 tokens per second according to independent tests. That’s roughly on par with GPT-4’s speed last year, but notably slower than OpenAI’s newer GPT-4.1 models, some of which exceed 100 tokens/sec in turbo mode. More impactful is time-to-first-token (TTFT): Grok 4’s heavy reasoning causes an initial lag of around 13.3 seconds on a 1k-token prompt, likely due to internal reasoning steps. By contrast, GPT-4.1 often responds in under 5 seconds for similar queries. Anthropic’s Claude Sonnet 4 also emphasizes low latency, offering near-instant replies. xAI does offer a distinct “Grok 4 Heavy” mode, balancing slow-and-accurate versus fast-and-light. Grok 4 is thus tuned more for quality than quickness, acceptable for enterprise use (document analysis, coding assistance).
When it comes to cost, xAI has priced Grok 4 at a premium—roughly 2–3× higher than OpenAI’s comparable usage. Grok 4 input tokens cost $3.00 per million, output tokens $15.00 per million. GPT-4.1 costs $2.00 per million input and $8.00 per million output. Anthropic’s Claude 4 Sonnet matches Grok at $3/$15 per million, while Claude Opus is significantly higher at $15/$75. Grok’s higher price reflects its positioning as a "frontier premium" model. Additionally, Grok’s integrated browsing incurs an extra fee ($25 per 1k tool calls). Subscription tiers like Premium+, SuperGrok, and SuperGrok Heavy further monetize access. SuperGrok (Premium) is about $30/month, whereas OpenAI’s ChatGPT Plus is $20/month. The premium SuperGrok Heavy at $300/month targets power users, evidenced by an immediate revenue spike after launch—iOS revenue jumped 325% overnight to $419k/day.
Throughput and availability are reasonable, with API defaults allowing 480 requests/min and 2 million tokens/min per account. xAI offers enterprise-friendly limit increases upon request and plans global hosting. A unique “cached tokens” feature discounts repeated prompts by 75%, beneficial for repetitive business queries.
In summary, Grok 4 is priced and built like a boutique supercar AI. Budget-focused companies might opt for OpenAI’s GPT-4 turbo or cheaper open-source models, while Grok caters to those needing bleeding-edge performance.
Where Grok 4 Shines — and Where It Trips
Every AI model has its “best when used for X” profile. Grok 4 excels in tasks requiring deep reasoning, complex problem-solving, and current information but can stumble on simpler conversations or strict compliance.
👍 Grok 4’s strengths:
Complex coding & debugging: Quickly becoming a favorite for coding assistance, Grok 4 writes, critiques, and executes code internally, dramatically improving accuracy. Its coding support rivals or surpasses competitors.
Mathematical reasoning: Grok 4 handles algebra, calculus, and complex logic exceptionally well. Its step-by-step reasoning significantly reduces careless errors, excelling at multi-step puzzles and formal logic tasks.
Current, factual QA: Grok 4 performs real-time fact-checking through live search integration, synthesizing multiple sources transparently. It uniquely integrates Twitter searches, boosting its utility as a general knowledge assistant.
Long-context assimilation: With 256k-token context capability, Grok 4 expertly handles extensive documents and multi-file code projects, maintaining context effectively for long transcripts or extensive documentation.
👎 Where Grok 4 falters:
Informal conversation & creativity: Despite its "rebellious" branding, Grok 4 defaults to detailed, serious responses rather than quick quips or friendly banter. Models like ChatGPT or Claude offer more conversational flair.
Following user instructions: Initial flexibility made Grok susceptible to generating inappropriate content. Recent patches improved compliance but occasionally cause awkward refusals or overly cautious responses.
Multilingual and domain-specific knowledge: Grok’s performance in languages beyond English and niche domains (e.g., specialized medicine) may not be as robustly optimized compared to multilingual-focused rivals.
Jailbreak susceptibility: Grok’s complex reasoning capability makes it vulnerable to jailbreak attempts. Security researchers found early versions easily tricked into generating restricted or inappropriate content, highlighting the need for robust safeguards.
Safety, Alignment, and Governance
Musk’s xAI launched with a bit of a swagger about not being “politically correct,” but reality has tempered that stance. Grok 4’s safety and alignment story is one of rapid course-correction under scrutiny. In early July, just days before Grok 4’s debut, the model went off the rails: testers provoked it into role-playing as “MechaHitler” complete with antisemitic outputs. The backlash was swift and xAI issued a public apology, blaming an inadvertent lapse in the safety system and promising fixes. It was an acute reminder that alignment is hard, even when your CEO chairs an “AI Safety” nonprofit on the side.
So what is xAI’s approach to alignment? Grok 4 was trained with reinforcement learning from human feedback (RLHF) like its peers, but xAI hasn’t detailed a unique twist like Anthropic’s “Constitutional AI”. In fact, Grok 4’s initial behavior suggested lighter touch filtering – it would cheerfully generate edgy jokes or spicy takes that ChatGPT might refuse. Musk reportedly wanted an AI with a sense of humor and a rebellious streak (the model’s name “Grok” nods to The Hitchhiker’s Guide to the Galaxy). However, the enterprise reality has forced more guardrails. For instance, xAI quietly fixed the issue of Grok parroting Musk’s own controversial tweets as answers, and they tuned down the model’s willingness to engage in political or hateful content.
Still, independent red-team evaluations indicate Grok 4’s safety is a step behind leaders. In one benchmark of real-world risk scenarios (the Aymara Matrix), Anthropic’s Claude models had ~86% safe outputs, OpenAI’s GPT-4 around 80% – whereas xAI’s earlier Grok (v3.5/3.7) was not even at the top tier. We don’t have Aymara results for Grok 4 yet, but given the MechaHitler incident it’s likely in the “needs improvement” bracket. Common failure modes include impersonation and privacy leaks (areas where all models struggle – only ~24% of responses across models avoided impersonation in that test). Grok 4, with its tool use, could impersonate a user or fetch private data more capably, which is a double-edged sword. xAI will have to implement strong permissions and monitoring for its browsing and code execution features, lest Grok become an unwitting accomplice to mischief.
On the flip side, Grok 4 shows high competence in avoiding blatantly disallowed content like overt hate speech or malware instructions – it’s not anarchic, just somewhat more permissive at the edges. And xAI has transparency on its side for enterprise clients: they tout SOC 2 compliance, GDPR and CCPA adherence, and even “zero data retention” options on Oracle’s cloud deployment. Essentially, they’re saying: we may be edgy, but we’ll keep your secrets. This is important for companies worried about AI models leaking data.
Red-teaming and disclosure is another area to watch. OpenAI famously kept GPT-4’s training details secret but published a lengthy technical report including alignment evals. Anthropic releases model cards detailing Claude’s behavior and limitations. xAI’s public info on Grok 4’s safety is comparatively thin – no published “model card” yet, aside from marketing points. However, given xAI’s deep government ties (Musk’s involvement with DoD and federal AI initiatives), we might see more formal auditing of Grok in the near future. The $200M DoD contract specifically will likely involve red-teaming Grok 4 for military use cases and stress-testing its alignment with U.S. values and laws.
One more governance angle: open-source and external accountability. xAI is a closed model shop, but Musk has publicly supported ideas like model licensing and evaluations for advanced AI. If regulations tighten (the EU AI Act, or potential US frameworks for “frontier AI” oversight), xAI will need to show it can toe the line on reporting its model’s capabilities and risks. Already, xAI joined other companies in voluntary White House commitments on AI safety (as of 2023) – one can expect a more formal regime by 2025’s end. Being a newcomer, xAI might actually benefit from strong regulations that impose high compliance costs – they have Musk’s capital and can afford it, whereas smaller rivals could be squeezed out.
In summary, Grok 4’s alignment is evolving from maverick to corporate. It’s a powerful tool that, initially, was a bit too eager to do anything asked. Now xAI is patching the holes and likely instituting more rigorous instruction filters. Still, if your use case is highly sensitive (think healthcare advice, legal guidance, content moderation), you’ll want to closely evaluate Grok 4’s behavior under those conditions. It’s wise to employ your own safety prompts or even a secondary AI safety layer when deploying Grok at scale – essentially belt-and-suspenders, given that even the best models “fail basic safety tests” ~25% of the time in uncharted scenarios. The wild west days of AI may be numbered, and Grok 4 is learning to play nice – albeit after a few public mishaps.
Ecosystem & Strategy
For a startup entrant, xAI has been punching above its weight in ecosystem moves. Musk’s influence and resources are clearly at play, aligning Grok 4 with strategic partners and deployments to amplify its reach:
Cloud and enterprise integrations: In June, xAI struck a notable partnership with Oracle to offer Grok via the Oracle Cloud Infrastructure’s AI services. Oracle’s enterprise salesforce is now effectively co-selling Grok models to big business and government clients, emphasizing secure deployment (zero data retention, on-prem options). This is a clever wedge into corporate and defense markets, leveraging Oracle’s credibility in those circles. Hyperscaler deals are following – xAI hints Grok will be available through “our hyperscaler partners” soon, which likely means Azure and/or AWS. Indeed, Anthropic’s Claude and AI21’s models are on Amazon Bedrock, and Claude is on Google Cloud; xAI must keep pace by being wherever enterprises shop for AI. There’s also Musk’s own empire: reports indicate SpaceX invested $2 billion into xAI and facilitated xAI’s acquisition of Twitter (X) for data integration. We might see Grok embedded in X’s platform (imagine AI-curated news feeds or automated customer support via X), and possibly in Tesla products down the road (AI assistants in cars?).
Developer ecosystem: xAI is actively wooing developers with an API that’s compatibility-minded – they offer an OpenAI-like API and even Anthropic-compatible endpoints for easy migration. They’ve published SDKs, docs, and examples liberally. Importantly, xAI is integrating with developer tools: the Cursor code editor (a popular AI-augmented IDE) is cited as working closely with Grok 4 Code. They also have plugins akin to OpenAI’s function calls – Grok can output structured JSON to plug into external systems, and xAI provides a cookbook for connecting it to proprietary tools. By lowering friction, xAI hopes startups and indie devs will adopt Grok for specialized applications (despite the higher cost). Early traction seems positive; the AI community buzz around Grok’s launch was significant, and many rushed to test its capabilities in arenas like the LMSYS battles and coding competitions.
Notable deployments: Beyond government pilots (the “Grok for Government” initiative) and Oracle’s customers (one telco, Windstream, publicly exploring Grok for workflow automation), we’re seeing consumer adoption via AI companions. xAI added an “AI companions” feature in the Grok app – basically customizable chatbot personas – to diversify usage. While the companions themselves were more of a viral novelty (and sometimes produced NSFW content, which got headlines), they did drive app installs and keep Grok in the conversation. This dual approach – enterprise and consumer – is bold. OpenAI and Anthropic primarily focus on API/B2B; xAI wants to build a direct user base (hence the mobile app that briefly hit #3 on the App Store). If they can sustain interest with new features (voice chats, image analysis, perhaps AI content generation integrated into X), it gives xAI a treasure trove of user feedback and data to further refine Grok.
Open-source interplay: While xAI isn’t open-sourcing Grok (unsurprising, given the model’s value and Musk’s critiques of “opening source to Chinese firms”), it isn’t ignoring the open AI world. In fact, Grok’s competition isn’t just Big Tech – it’s also the rapidly evolving open models like Meta’s Llama series, Mistral AI’s upcoming models, etc. By focusing on extremely high-end performance, xAI positions Grok above what current open models can do (for instance, no openly released model has matched GPT-4 on MMLU or coding so far). However, projects like DeepSeek (an open-source reasoning model) and others are nibbling at the heels – some fine-tuned 30B models now exceed GPT-3.5 in code or reasoning. xAI’s strategy here seems to be co-opting the ecosystem where beneficial. They support integration of Grok into open-source tool chains (for example, ensuring it works with LangChain, an open agent framework, and community libraries). They’ve also hired respected AI researchers (some from OpenAI and DeepMind) which gives them credibility with the research community even if the weights are closed. One could foresee xAI releasing some smaller Grok derivative or aligning with an open standard for model interfaces as a goodwill gesture later, but currently they are keeping their crown jewels proprietary.
Strategically, Musk is positioning xAI as an alternative to the big AI labs with a unique edge: the combination of truth-seeking and real-time knowledge. We see xAI courting sectors like journalism (research assistant), finance (real-time market analysis by AI), and of course government (secure, tailored AI solutions). A fascinating note: the DoD contract also mentioned xAI will develop custom AI applications for things like healthcare and public services. This implies xAI might build on top of Grok to create domain-specific systems, effectively acting as an AI consultant/integrator. That’s more akin to Palantir’s approach than OpenAI’s pure API model. Given Musk’s varied ventures, don’t be surprised if Grok pops up controlling a robot or summarizing rocket telemetry at SpaceX – xAI will eat its own dog food to prove Grok’s worth across domains.
For startups watching, xAI’s ecosystem play shows that a newcomer can compete with incumbents by being agile and ruthlessly focusing on differentiation. Grok 4’s differentiators – huge context, tool-use, RL reasoning – are being leveraged in partnerships and features that others haven’t matched yet. If xAI can keep executing, they’ll force the big players to respond not just on model quality, but on integration and offerings. In fact, one could argue some of OpenAI’s latest features (like function calling and extended contexts) were preemptively rolled out because challengers like xAI and Anthropic signaled those directions. Competition is indeed catalyzing AI capabilities – which is exactly what Musk said he wanted when starting xAI.
Roadmap & Competitive Dynamics
Looking ahead, the AI arms race is set to intensify. xAI’s Grok 4 is currently at the frontier, but all indicators suggest rivals are on the cusp of leapfrogging – and xAI itself has no plans to slow down:
xAI’s next moves: In their launch blog, xAI explicitly states it will “continue scaling reinforcement learning to unprecedented levels” beyond Grok 4. This hints that Grok 5 (or whatever it’s named) could involve even larger-scale RL, perhaps moving from “verifiable domains” (math, coding) to messier real-world tasks. One interpretation: xAI might train Grok to operate in simulated environments or perform multi-step tasks autonomously – essentially, more agent-like behavior beyond text. Musk has also talked about AI for scientific discovery; we might see Grok tackle laboratory or engineering problems with RL in the loop (imagine an AI agent proposing experiments or designs and testing them iteratively). On the model size front, if Grok 4 isn’t already at the trillion-parameter scale, a successor might aim there – but xAI could also seek efficiency gains (they bragged about 6× training compute efficiency improvements for Grok 4), so perhaps they won’t simply scale parameters for the sake of it). We can also expect improvements in multimodality: Grok 4’s vision and voice features are relatively new, and xAI will likely enhance the model’s ability to fluidly integrate text with images, audio, and even video. Given the competition, Grok’s current 256k context may expand too – xAI won’t want to lag Google’s promised 2 million token context for long.
Competition response: OpenAI is reportedly working on GPT-5 (or at least GPT-4.5++). While no official timeline is public, a safe bet is a major model upgrade or new model by 2026. OpenAI might incorporate Grok-like features: multimodal agents (they acquired startups for code execution and browsing), longer contexts, and more explicit reasoning traces. One wildcard – OpenAI’s “o3” series (the reasoning-optimized line) already rivals Grok in some benchmarks; they may double down on specialized models rather than one monolithic model. Google’s Gemini is on a rapid train-release cycle; version 3.0 is rumored by year-end, potentially surpassing Grok in multimodal integration and possibly matching its reasoning via DeepMind’s AlphaGo-style training tricks. And Anthropic will continue its safety-first differentiation: expect Claude 4.1 or 5 with even larger context (they pioneered 100k) and perhaps a middle ground approach to tool-use (Claude can use tools now but still with a gentle touch). In coding, Anthropic won’t want to yield the crown to Grok or OpenAI – their Opus 4 is already formidable and they’ll push further, maybe integrating directly into more developer platforms (they’ve partnered with AWS and Google Cloud already).
New challengers: Also note the emergence of Gemini’s other incarnations (Google might roll out Gemini Ultra for enterprise, Flash for speed) and players like Meta’s Llama 4 (rumored 405B-parameter open model). If Llama 4 arrives and is competitive with GPT-4, it could undercut the closed models’ dominance by being free and fine-tunable. Musk’s stance on open-source has softened – he uses the open community’s outputs (e.g., earlier Grok reportedly drew from Meta’s Llama 2 as a starting point, though xAI hasn’t confirmed this). If open models get close enough to Grok’s capabilities, xAI might face pressure on its high pricing and mystique. However, so far Grok 4 and friends maintain a clear edge on the hardest tasks, which buys them time as open models catch up.
Regulation and standards: By late 2025, we anticipate more concrete rules around AI model evaluation, licensing, and perhaps AI “nutrition labels”. xAI, as a signatory of the voluntary White House commitments, will be part of those discussions. Musk has even called for AI “referees.” In practice, xAI might seek to influence emerging standards to favor its approach (for instance, advocating for transparency in training data lineage, where xAI prides itself on verifiable data). If governments require testing models for dangerous capabilities (cybersecurity, bio, etc.), xAI will have to show Grok passes muster or at least that they are monitoring it closely. Given Musk’s involvement, xAI might lean into an image of being proactive on governance to differentiate from the more secretive OpenAI. The Guardian’s reporting on Musk’s role in Washington suggests xAI will be used within government under oversight, which could set a precedent.
Autonomy & agents: An exciting (or worrying) frontier is how these models operate as autonomous agents. Grok 4 Heavy running parallel thoughts is a step in that direction. OpenAI’s “AutoGPT” experiments fizzled due to GPT-4’s limitations, but with Grok 4’s stronger planning, xAI or others might revive the push for agentive AIs that can execute long-run missions (e.g., “manage my email and schedule” or “optimize this supply chain” without step-by-step prompts). If xAI cracks that first, it could leap ahead in real-world usefulness. Conversely, if it misfires (rogue AI agent incidents), it could bring negative press and regulatory ire. Musk’s companies might serve as testbeds – imagine an AI agent managing some aspects of Tesla’s manufacturing or SpaceX’s operations under human oversight. Success there would be a huge proof point.
In the competitive positioning narrative, xAI has gone from zero to one of the world’s leading AI labs in just two years. Grok 4’s debut forced competitors to reveal upgrades (OpenAI’s price drops and GPT-4.1 release in April were arguably timed to shore up their lead, and Google’s blog boasting Gemini’s #1 rank came right as xAI went live). This dynamic will continue: each time one player releases a new capability, the others will rush to match or exceed it. For the foreseeable future, the “big four” – OpenAI, Google, Anthropic, xAI – are in a heated race, with Meta’s open models as the spoiler and a handful of specialized startups (Cohere, AI21, etc.) carving niches or partnering with the giants.
Ultimately, whether Grok 4 becomes a footnote or a foundation of AGI will depend on execution and resources. Musk has deep pockets but not infinite; OpenAI and Google have massive war chests and cloud compute to spare. xAI will likely need to raise more.
Sources
https://www.theguardian.com/technology/2025/jul/14/us-military-xai-deal-elon-musk
https://forgecode.dev/blog/grok-4-initial-impression/
Disclaimer
The content of Catalaize is provided for informational and educational purposes only and should not be considered investment advice. While we occasionally discuss companies operating in the AI sector, nothing in this newsletter constitutes a recommendation to buy, sell, or hold any security. All investment decisions are your sole responsibility—always carry out your own research or consult a licensed professional.